

Trouve ton prochain déclic
Six univers pour passer à l’action et bâtir ton business digital propulsé par l’IA.
Les derniers articles
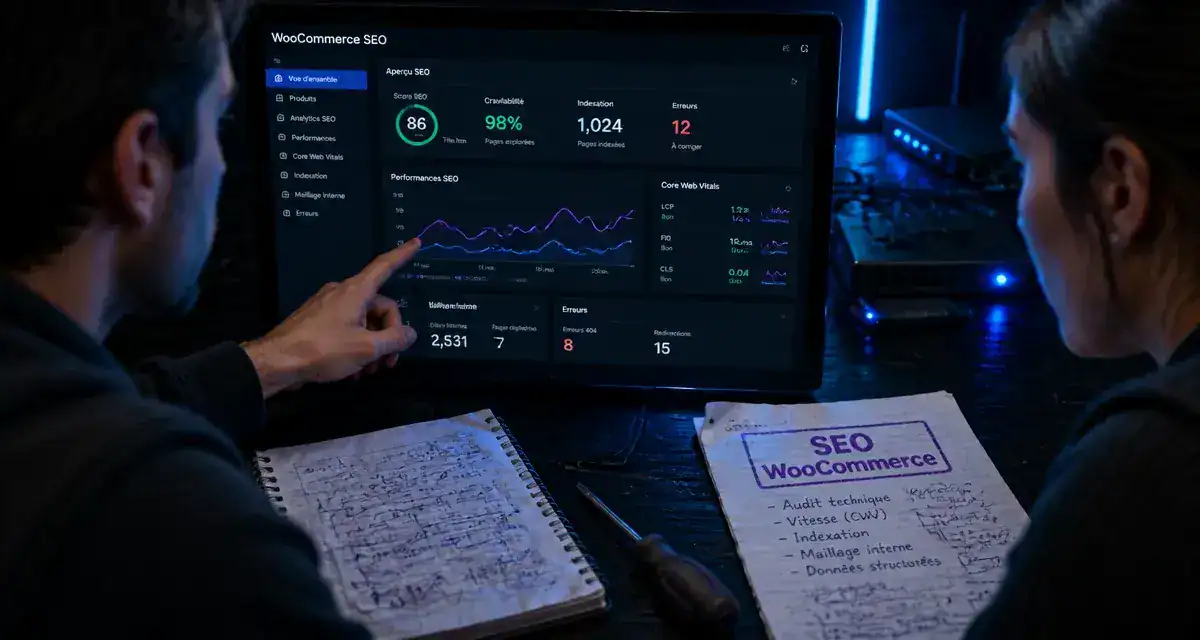
Agence SEO WooCommerce : 4 leviers techniques pour transformer votre boutique en machine à vendre
Découvrez comment une agence SEO WooCommerce utilise 4 leviers techniques pour transformer votre boutique en ligne en une machine à vendre performante et rentable.

Smartphone pliable : 2 formats, 5 modèles phares et les pièges à éviter avant l’achat
Les smartphones pliables offrent deux formats majeurs, clapet et livre, avec 5 modèles phares. Ce guide détaille usages, performances et points à surveiller avant achat.

Indexation WordPress : 4 étapes techniques pour apparaître sur Google
Apprenez à rendre votre site WordPress visible sur Google grâce à 4 étapes techniques essentielles : réglages de visibilité, Google Search Console, optimisation technique et gestion des erreurs.

Comparatif tablettes 10 pouces : 4 modèles pour choisir selon vos besoins
Comparez 4 tablettes 10 pouces phares : iPad Air, Samsung Galaxy Tab S9 FE, Xiaomi Pad 6 et Lenovo Tab M10 Plus. Choisissez selon usage, performance et budget.

Optimiser le SEO : 3 piliers techniques et stratégies de maillage pour dominer Google
Maîtrisez l’infrastructure technique, l’architecture sémantique et le netlinking pour optimiser votre SEO et apparaître en première page de Google durablement.